 |
| Thanks to Leah for permitting me to cite her here by name. |
We share 170 cM which looks promising enough that FTDNA suggests that we may be second-third cousins, though I know that is highly unlikely. Our longest segment is only 8 cM, which pretty much disqualifies this as a match at all. It means that we have at least twenty-one segments of 8 cM or smaller, many of which are undoubtedly false - not indicative of any relationship whatsoever - with the others perhaps reflecting some very distant common ancestors.

It looks even more obscure when I look for Leah among the matches of my five siblings. Two of my sisters do not show up as matches at all. The other two and my brother are estimated by FTDNA to be Leah's fifth-remote cousins.
But since I had already begun looking at the match, I asked Leah about uploading to GEDmatch/Genesis. Genesis tells me that Leah and I share 29.8 cM, quite a drop-off from FTDNA's 170. It is no surprise that there is a difference, FTDNA counts very small segments and GEDmatch does not. Those very small segments are not worth much, so advantage GEDmatch.
But there are differences in the algorithms, as well, and I thought it would be useful to revisit that here. For that I looked at my five Kwoczka cousins, descendants of my great-grandmother's two brothers. I compared them to my father's brother, as I myself match only four of the five on Family Finder.
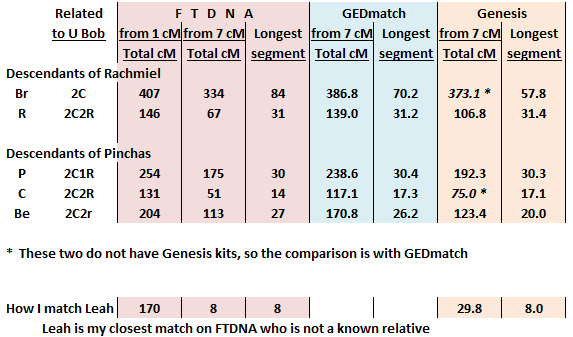
The adjustment of the FTDNA threshold from 1 cM to 7 cM lowered the Kwoczka cousins' matches with Uncle Bob by 73-91 cM. Leah's matches with me went down by 162 (!) cM, about twice as much.
The total matches on GEDmatch are significantly larger than the 7 cM FTDNA matches. I think this has to do with the algorithms.
The Genesis matches are somewhere in between - smaller than the original GEDmatch but larger than FTDNA.
One of the oddities here is the longest segment. There might be some algorithm issue, but there should be no threshold issue. For three of the Kwoczka cousins, there is no significant difference between FTDNA and GEDmatch. For the match between Uncle Bob and Cousin Br, the longest segment according to FTDNA goes from 24,778,179 to 112,771,988. The GEDmatch numbers are very close to these, though the length in cM at FTDNA is 20% greater than at GEDmatch.
The more significant difference is between GEDmatch and Genesis. They start and end at about the same places, but Genesis has a break in the middle, such that GEDmatch gives us a length of 70.1 cM while Genesis has two segments totalling 66.7 cM - nearly the same.

The longest segment between Uncle Bob and Be is different. FTDNA and GEDmatch show near identical results, but Genesis is about twenty-five percent lower. But it is not because of a gap in the segment.

I long ago decided that I don't really need to know why these results are different from one company to another. I just have to choose one and work with it. So now that GEDmatch has moved on from the old standard, Genesis is where it's at.
Housekeeping notes

European Jews have always married mainly within the tribe. Whether our numbers five hundred years ago in Europe were four hundred or four hundred thousand, the pool was limited. As a result, the members of the tribe today are all related to one another, multiple times. This phenomenon, known as endogamy, makes Jewish genetic genealogy very difficult, often impossible. There is a similar phenomenon in some other population groups.
I was convinced that this brick wall is not as impenetrable as it seems, at least in some circumstances.
I believe that this book demonstrates that I was correct.
When I decided I wanted to write a book, I was not sure if I wanted to write a “How to” book or a “How I did it” book. The decision was dictated by the facts in the field. Different family structures, widely different numbers of living family members, and other similar factors dictated that writing “How to” would be irrelevant for most researchers.
“How I did it” is more likely to be helpful to the research community and more likely to instill the confidence necessary for such a project.
It is my hope that this book will encourage and inspire other researchers of their European Jewish families and other endogamous populations to say “I can do this!”
No comments:
Post a Comment